Куда «исчезают» ресурсы, владельцам которых надоело развивать свой проект, платить за домен и хостинг, вкладывать усилия в монетизацию, не получая желаемых результатов?
Они упаковываются в архив и хранятся на специализированном сервисе. Как правило, владельцы сайтов не дают разрешение на хранение своего архивированного проекта и тем более, на доступ к нему сторонних лиц. Поисковые роботы по своей инициативе периодически проверяют все сайты и регулярно производят их архивацию, которую отправляют в хранилище.
Что такое вебархив сайта
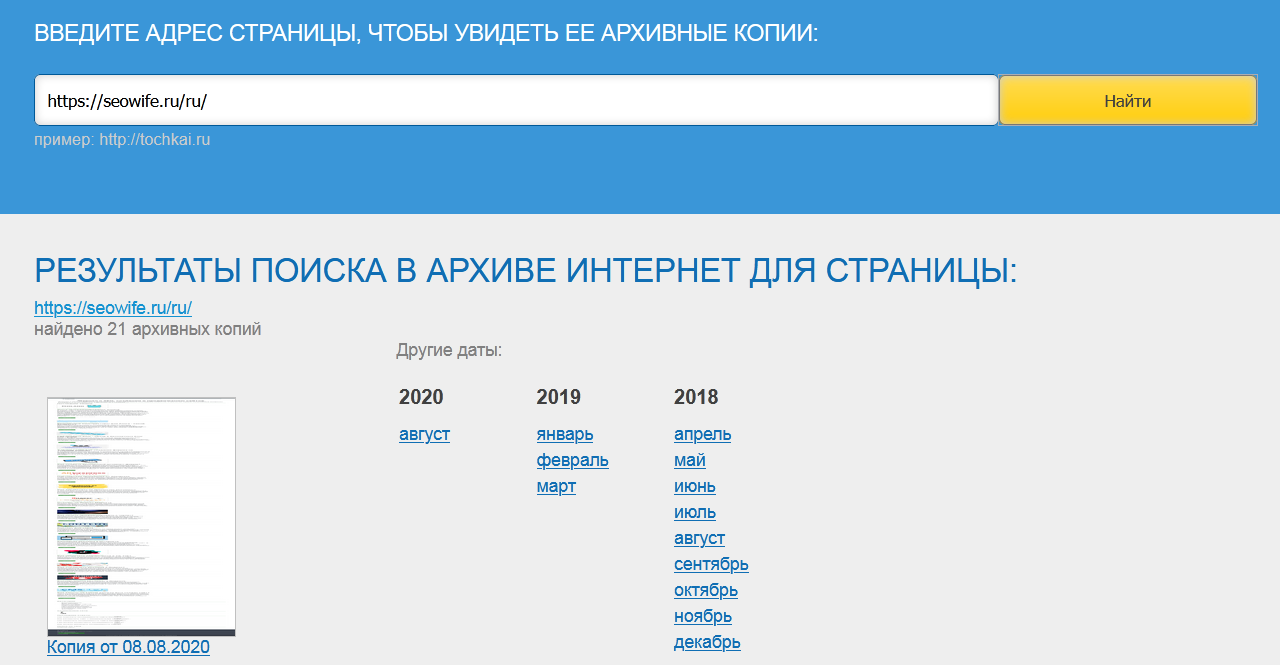
Этим термином называют цифровые копии сайтов, упакованные в архив с сильным сжатием, и сервисы с таким же названием. Среди них есть версии на русском языке.
Сайты представляют собой наследие интернета. Компания, создавшая главный сервис-архиватор Internet Archive Wayback Machine (коротко «Вебархив»), взяла на себя ответственную миссию по сохранности всех проектов. Некоторые из них содержат ценный контент. Как правило, для каждого ресурса создается несколько копий, можно восстановить любую из них, а не только последнюю.
Наряду с главным хранилищем web-arhive.ru, существуют и другие площадки, помогающие «достать» блог из архива.
Владельцы могут пожалеть о том, что забросили свой проект. Нужно просто запустить поиск по вебархиву, введя домен в поисковую строку. Заархивированный ресурс можно распаковать сразу на хостинг или скачать на свой компьютер, чтобы локально, без использования услуг хостера, проверить и подкорректировать страницы. Для тестирования нужно установить на компьютер XAMPP-сервер, при инсталляции указать PHP или Apache.
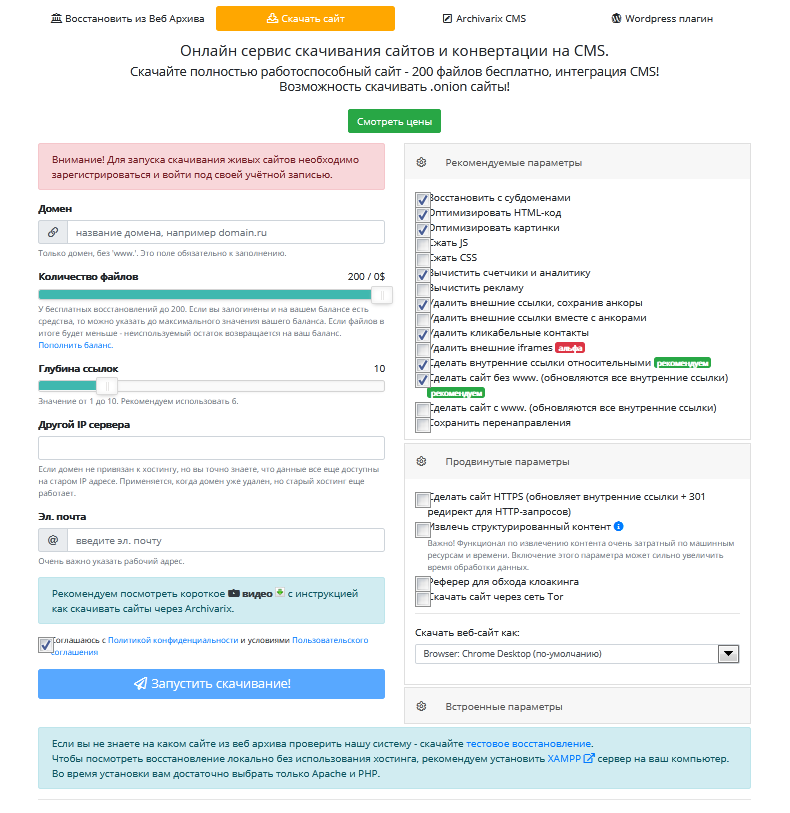
Блог в архиве сохраняется таким (дизайн страниц, контент, навигация), каким его роботы видели каждый раз, создавая слепок во время очередного сканирования. Можно скачать старую версию до обновления дизайна, до смены шаблона, если владелец помнит дату обновления.
Как восстановить сайт из вебархива
(на примере сервиса archivarix.com)
Услуга платная, цена зависит от размера ресурсов — от количества файлов в архиве. Небольшие проекты, содержащие менее 200 файлов, можно восстановить бесплатно. Далее происходит градация цены по численности файлов:
-
до 1200 — фиксированная сумма, $5 за тысячу.
-
свыше 1200 — дополнительно начисляется по полдоллара за каждую последующую тысячу.
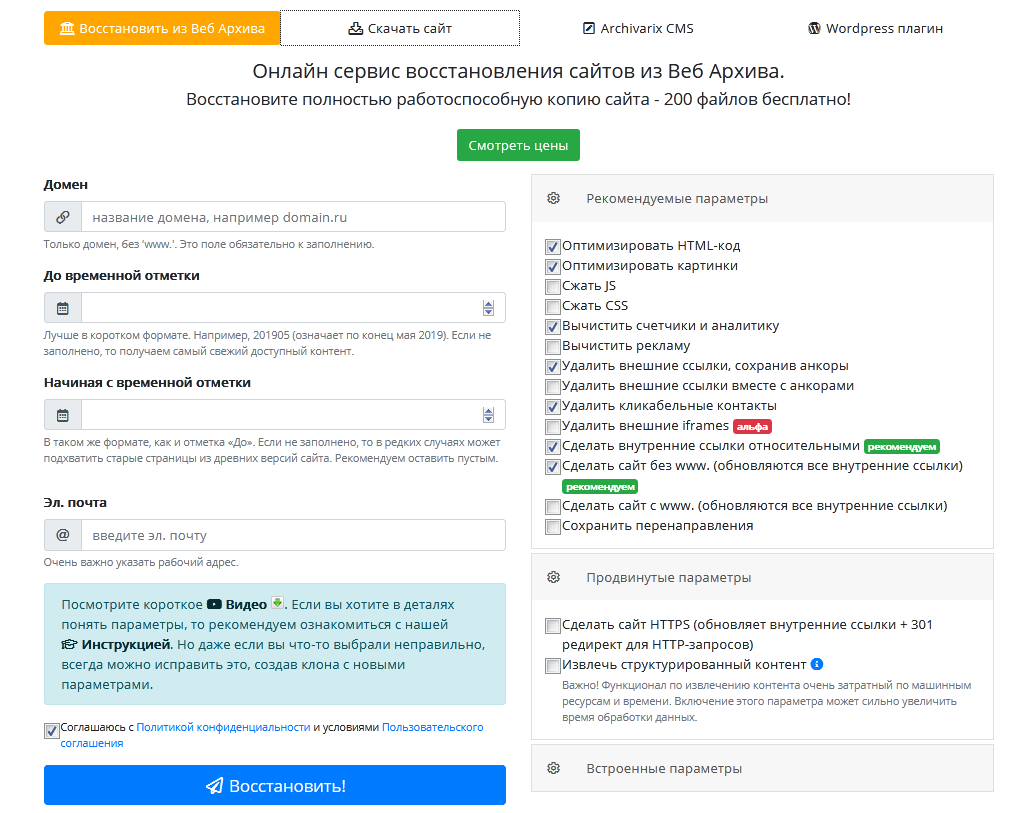
При восстановлении сайта из вебархива https://archivarix.com/ru/, нужно:
-
Прочесть Пользовательское соглашение, ознакомиться с Политикой конфиденциальности.
-
Заполнить несколько полей: указать домен, временную отметку (дату), свою электронную почту.
-
Нажать кнопку «Восстановить».
На сервисе дается инструкция и видео, где подробно объясняются все моменты, как восстановить из вебархива нужный блог.
Уникальны ли статьи из вебархива
Продавцы, которые предлагают извлеченные статьи из вебархива, утверждают, что они абсолютно уникальны. Но, такой контент может содержать:
-
элементарные грамматические ошибки;
-
устаревшие сведения, давно утратившие актуальность;
-
недопустимо вписанные ключи по канонам двадцатилетней давности (Москва купить бетон отгрузка; швейцарские часы золото дорого).
Старые тексты нуждаются в вычитке и редактировании, что большинство продавцов не удосуживаются сделать.
Стоит ли извлекать тексты из вебархива самостоятельно с помощью программ-парсеров, чтобы упростить задачу обновления контента на своем сайте?
Статьи могут плохо индексироваться, вообще не попасть в индекс или быстро оттуда выпасть. После очередного апдейта поисковой системы их уникальность может упасть до 2–5 %. Старые тексты можно использовать как основу для рерайтинга, создавая на их базе современные статьи, добавляя свежие факты и ценные данные.
Поисковые гиганты легко определяют заимствованный контент вебархива. При проверке уникальности они выдают процентное сходство, указывая проекты, хранящиеся в архивах.
Возможно ли удалить сайт из вебархива
Зачем удалять свой дневник из web-архива?
Любой новичок, впервые создавший свой блог и ощутивший себя вебмастером, испытывает гордость. Но, позже, заведя несколько проектов, он понимает, какими несовершенными, кривыми и косыми были первые опыты. Хочется их устранить, чтобы никому не попадались на глаза.
Как удалить сайт из вебархива?
На просторах сети часто встречаются советы: нужно добавить запрет на архивирование в robots.txt:
User-agent: ia_archiver-web.archive.org
Несмотря на такие записи, роботы игнорируют директивы. Сайты все равно архивируются и попадают в хранилище Internet Archive. Убрать их оттуда можно только одним способом: написать письмо в службу поддержки сервиса и попросить удалить свой блог из базы данных, указав его название.
При этом:
-
Придется подтвердить, что вы являетесь владельцем или, хотя бы, автором контента. Указать, где на сайте отображены данные о вас (имя блогера, ник автора под статьями, контактные данные).
-
В качестве подтверждения переслать сообщения от регистратора доменных имен или от службы хостинга — документы, которые докажут, что вы являетесь владельцем домена.
-
Адрес, с которого отправляется письмо, должен совпадать с электронной почтой домена или с ящиком, указанным в логотипе либо в футере блога.
-
Возможно, придется подтвердить личность — прислать фотографию, сведения о себе: дату рождения, адрес, телефон.
Только так удастся вытащить сайт из вебархива. Если саппорт устроят предоставленные вами доказательства, проект будет навсегда удален из сети, он перестанет отображаться в поиске по архивам.
